CARLA-SUMO 协同仿真强化学习框架:让自动驾驶汽车学会主动换道
1. 引言:为什么需要协同仿真?
训练自动驾驶换道策略,面临一个根本矛盾:
- CARLA 提供高保真的车辆动力学仿真——发动机响应、轮胎摩擦、悬架动态,精确到物理层面。但它默认只有主车是自动驾驶的,背景交通需要手动配置。
- SUMO 擅长大规模交通流仿真——可以轻松生成成百上千辆背景车,模拟真实城市交通的拥堵、跟驰、换道行为。但 SUMO 的车辆模型是宏观的,缺乏动力学细节。
单独用任何一个,都不够。
如果只用 CARLA,背景交通稀疏,换道决策缺乏挑战性。如果只用 SUMO,车辆行为太”规矩”,无法学到真实的动力学响应。
于是,协同仿真成了最优解——CARLA 管主车的动力学,SUMO 管背景交通流,通过 TraCI 协议实时同步状态。这正是本项目的核心设计。
2. 系统架构:双仿真器是如何协同的?
2.1 并行架构
CARLA 和 SUMO 作为两个独立进程运行,通过 Python 接口(CARLA Python API + TraCI)进行通信。整个系统的数据流如下:
┌─────────────┐ TraCI ┌─────────────┐
│ SUMO │ ←────────────→ │ CARLA │
│ (交通流) │ 状态同步 │ (动力学) │
└─────────────┘ └─────────────┘
↑ ↑
│ │
└─────── 主车状态双向同步 ───────┘
(BridgeHelper)- SUMO 负责背景车辆的生成、移动、换道,以及交通规则层面的决策。
- CARLA 负责主车(Ego Vehicle)的精确动力学响应——加速、制动、转向的实际物理效果。
- BridgeHelper 是两个世界的”翻译官”,负责坐标系转换(左手坐标系 ↔ 右手坐标系)、位置平移、朝向角反转。
2.2 时间同步机制
协同仿真的核心是一个严格的顺序同步函数 _sync_world:
def _sync_world(self):
# 1. 推进 SUMO,获取所有交通参与者状态
sumo_sim.tick()
# 2. SUMO → CARLA:同步背景车辆位置
self._sync_sumo_to_carla()
# 3. 推进 CARLA,应用主车控制指令
carla_sim.tick()
# 4. CARLA → SUMO:同步主车位置回 SUMO(幽灵车)
self._sync_carla_to_sumo()每步仿真长度为 0.1 秒(STEP_LENGTH = 0.1),在精度和效率之间取得平衡。
2.3 主车控制机制
主车通过 CARLA 的 Traffic Manager (TM) 接管。TM 配置了几个关键参数:
set_synchronous_mode(True)— 同步模式,确保 TM 与仿真步同步- 禁用自动换道 — 换道决策 100% 由强化学习策略控制
- 跟车距离 3.0 米 — 保持安全跟车距离
- 忽略交通信号灯 — 简化决策场景
当策略输出换道动作时,通过 force_lane_change 发送强制换道指令,同时设置 40 步(约 4 秒)的换道冷却时间。
3. 强化学习算法:PPO
3.1 为什么选 PPO?
本项目采用 Proximal Policy Optimization (PPO) 算法,由 Stable-Baselines3 库实现。选择 PPO 的核心理由:
- 稳定性强:通过 Clip 机制限制策略更新幅度,避免因单次过大更新导致性能崩溃
- 超参数鲁棒:不需要大量调参就能收敛,适合工程落地
- 支持连续/离散混合空间:虽然本项目将动作离散化,但 PPO 的框架天然支持更复杂的动作空间扩展
PPO 的目标函数为:
其中
3.2 网络结构
策略网络采用 MlpPolicy(多层感知机):
- 共享特征层:两个 128 单元的全连接层 + ReLU 激活
- 策略头:输出 3 维离散动作的对数概率
- 价值头:输出状态价值估计
训练超参数:
| 参数 | 值 |
|---|---|
| 学习率 | 3e-4 |
| GAE λ | 0.95 |
| 折扣因子 γ | 0.99 |
| 每轮步数 n_steps | 2048 |
| 批次大小 | 64 |
| 熵系数 ent_coef | 0.01 |
4. 动作空间与观测空间
4.1 动作空间(3 维离散)
| 动作 | 值 | 行为 |
|---|---|---|
| 保持车道 | 0 | 当前车道匀速行驶 |
| 向左换道 | 1 | 向左侧车道发起换道 |
| 向右换道 | 2 | 向右侧车道发起换道 |
4.2 观测空间(14 维连续向量)
观测向量包含三类信息:
主车状态(3维)
- 纵向速度
(归一化) - 横向速度
(归一化) - 目标巡航速度(归一化,TARGET_SPEED = 50 km/h)
周围车辆感知(10维) 采用 5 通道传感器配置,每个通道返回「最近车辆距离」+ 「相对速度」:
[左后] [左前]
↑
[后] ←—— [主车] ——→ [前]
↓
[右后] [右前]道路信息(1维)
can_l:左侧车道是否可换道(布尔)can_r:右侧车道是否可换道(布尔)st_code:换道冷却状态
5. 奖励函数设计
奖励函数是策略学习的核心驱动力。本项目采用稠密奖励 + 稀疏激励的混合设计:
5.1 各分量奖励
速度奖励(r_speed)
达到目标速度 50 km/h 时,奖励为 1.0;速度越低,奖励越少。
堵车惩罚
这是驱动智能体主动换道的核心动力——被困在慢车后面会持续扣分。
换道成功奖励
当且仅当:换道冷却结束后 35 步内检测到车道变化,才算成功换道。高额奖励建立了”换道→成功”的强关联。
安全惩罚
碰撞是高压线,任何情况下都不可接受。
5.2 奖励信号解析
为什么这样设计?
堵车惩罚设得不太重(-0.5),是因为如果太重,智能体会”宁可撞车也要换道”;而碰撞惩罚设得极重(-50),是因为安全性必须压倒一切。通过多分量加权组合,策略最终学会:在安全的前提下,积极换道以避免拥堵。
6. 训练结果与分析
6.1 训练配置
- 地图:CARLA Town06(城市道路,双向多车道)
- 仿真步长:0.1 秒
- 目标训练步数:100 万步(1M steps)
- 设备:CPU 训练(GPU 加速主要受益于物理仿真的并行性)
- 检查点保存:每 10,000 步保存一次
6.2 训练曲线
经过 27 万步的训练(对应约 7.5 小时),智能体已经展现出清晰的换道能力:
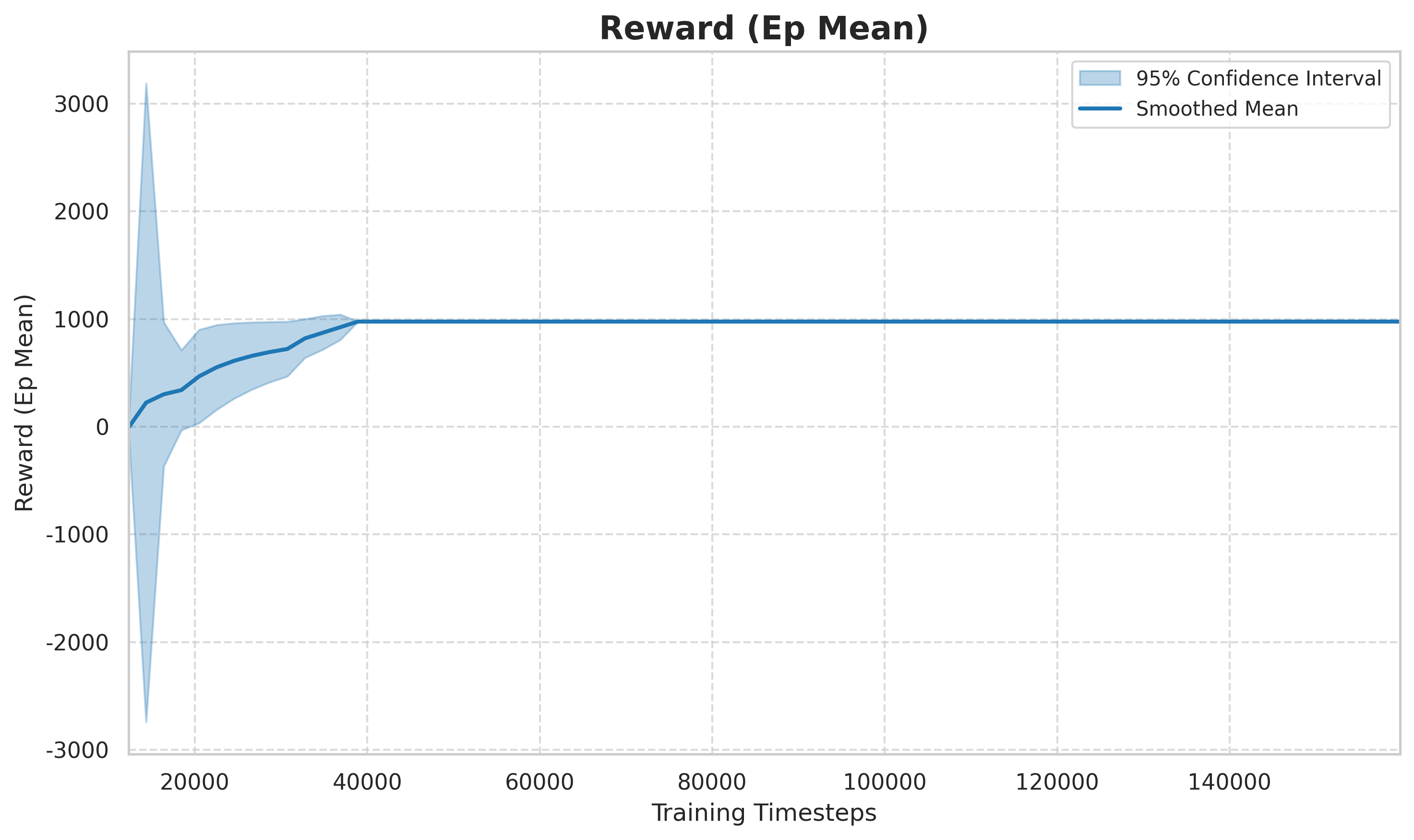
图:每回合平均奖励(episode reward mean)随训练步数的变化。早期(0
50k 步)奖励波动剧烈,智能体处于随机探索阶段;中期(50k150k 步)奖励快速上升,策略逐渐学会换道以获得更高速度奖励;后期(150k+ 步)趋于收敛,策略接近次优解。
6.3 价值损失与策略损失
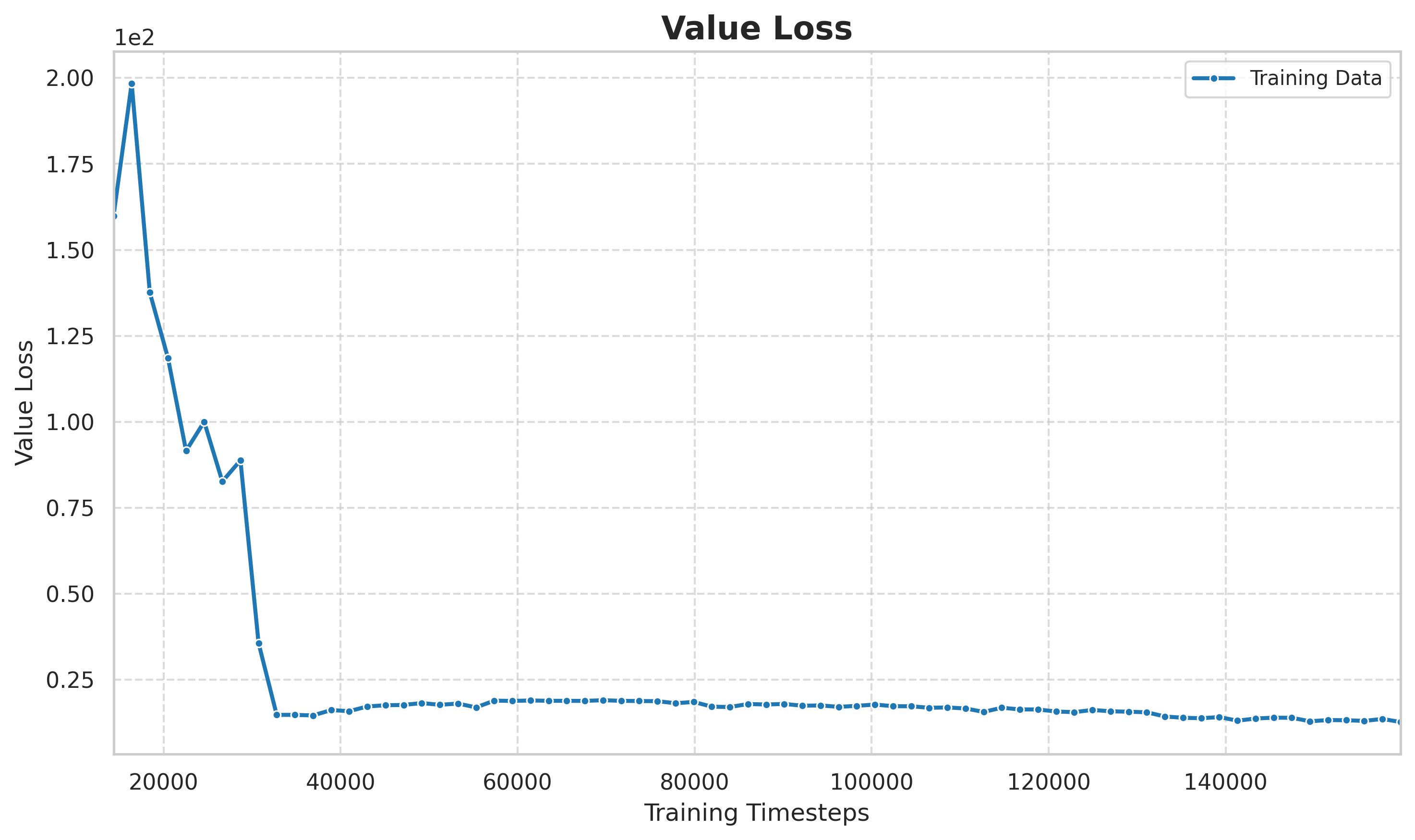
图:价值网络损失(value loss)随训练步数的变化。初期损失较高,价值网络还在学习估计状态价值;中后期损失稳定在较低水平,说明价值估计趋于准确,为优势函数提供了可靠的基线。
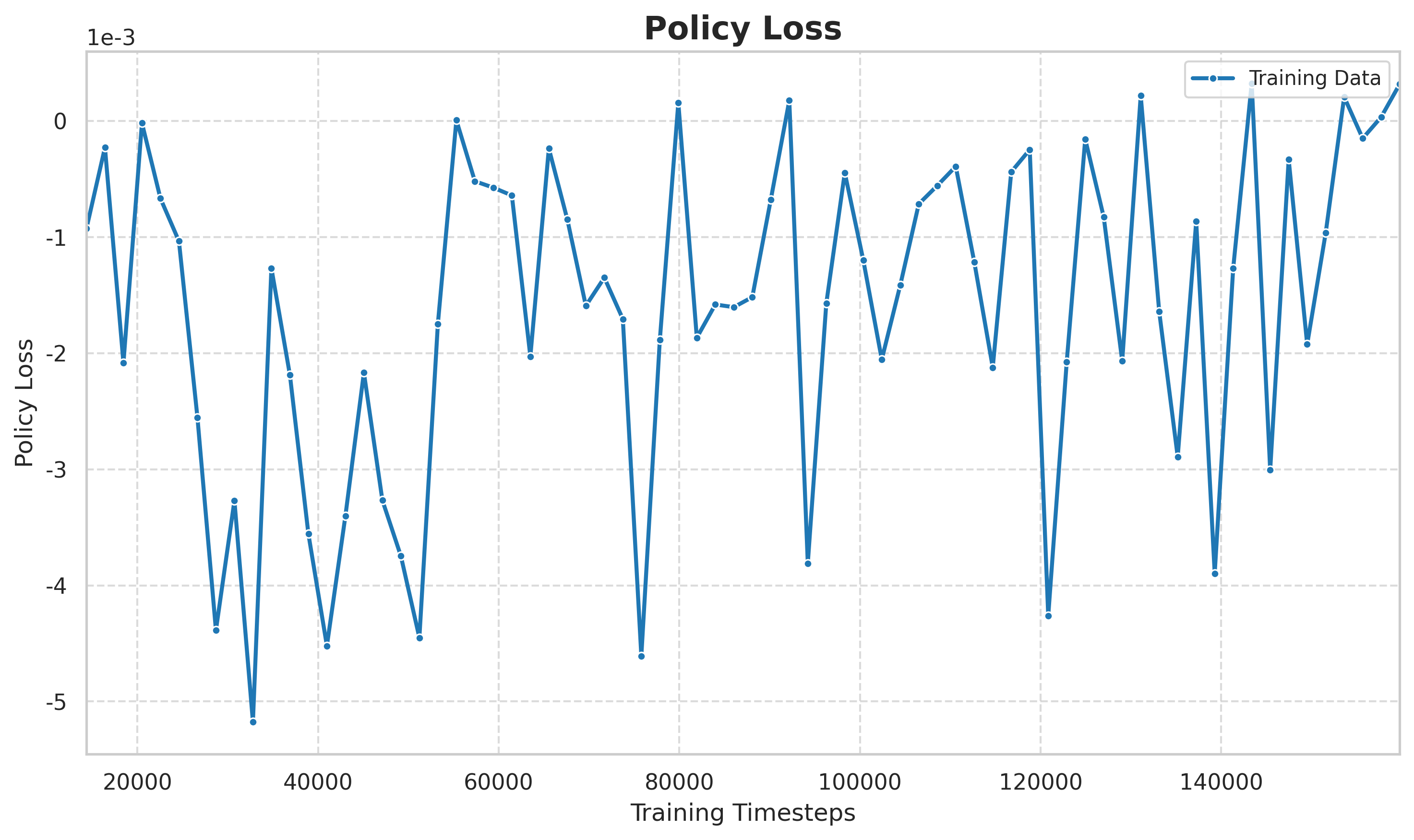
图:策略损失(policy loss)曲线。PPO 的策略损失直接反映策略更新的方向和幅度,可以看到策略在探索-利用之间动态调整。
6.4 速度对比分析
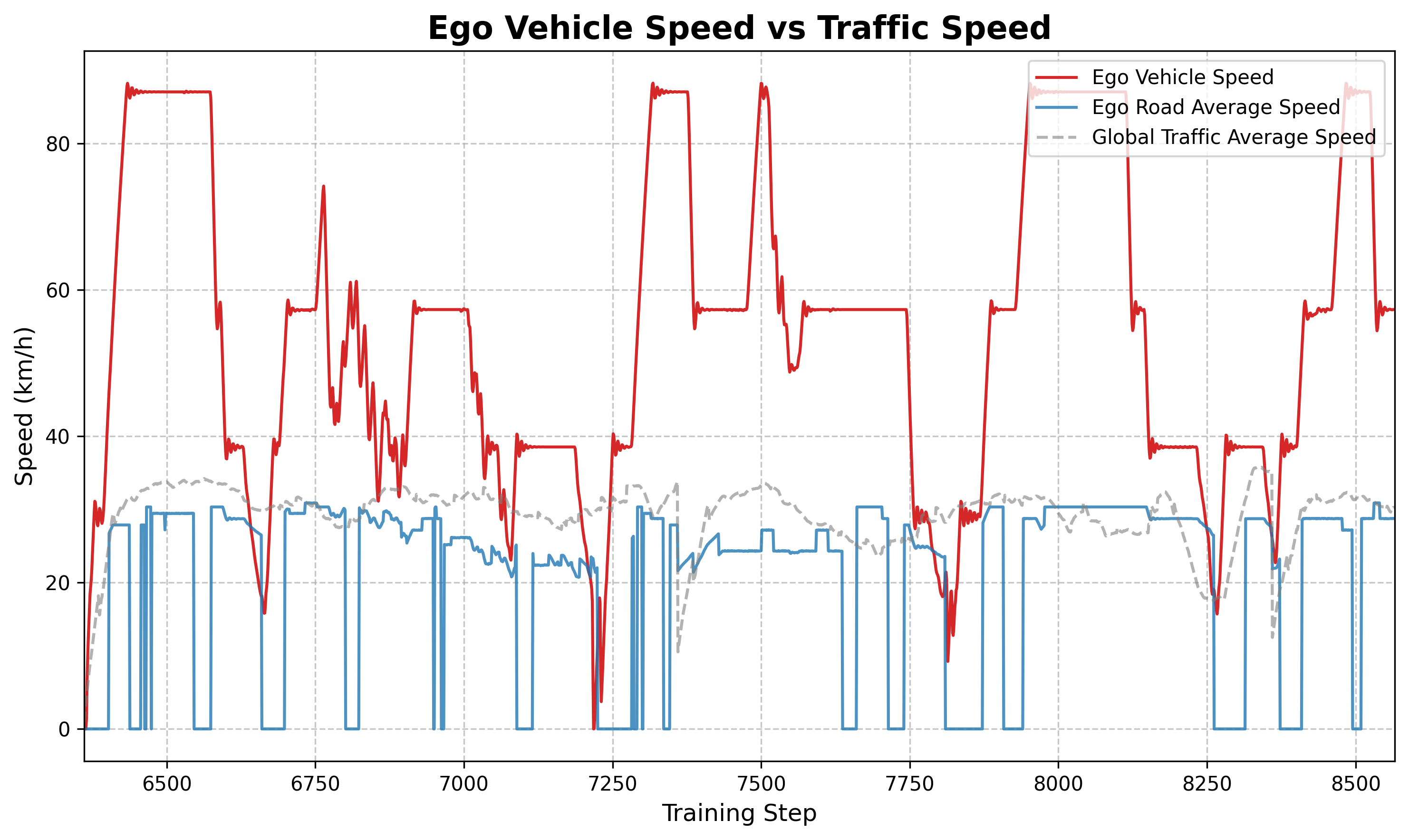
图:主车速度(橙色)vs 道路平均速度(蓝色)对比。可以观察到主车速度整体高于交通流平均速度,说明策略学会了主动寻找高速车道或摆脱低速拥堵。
6.5 换道频率分析
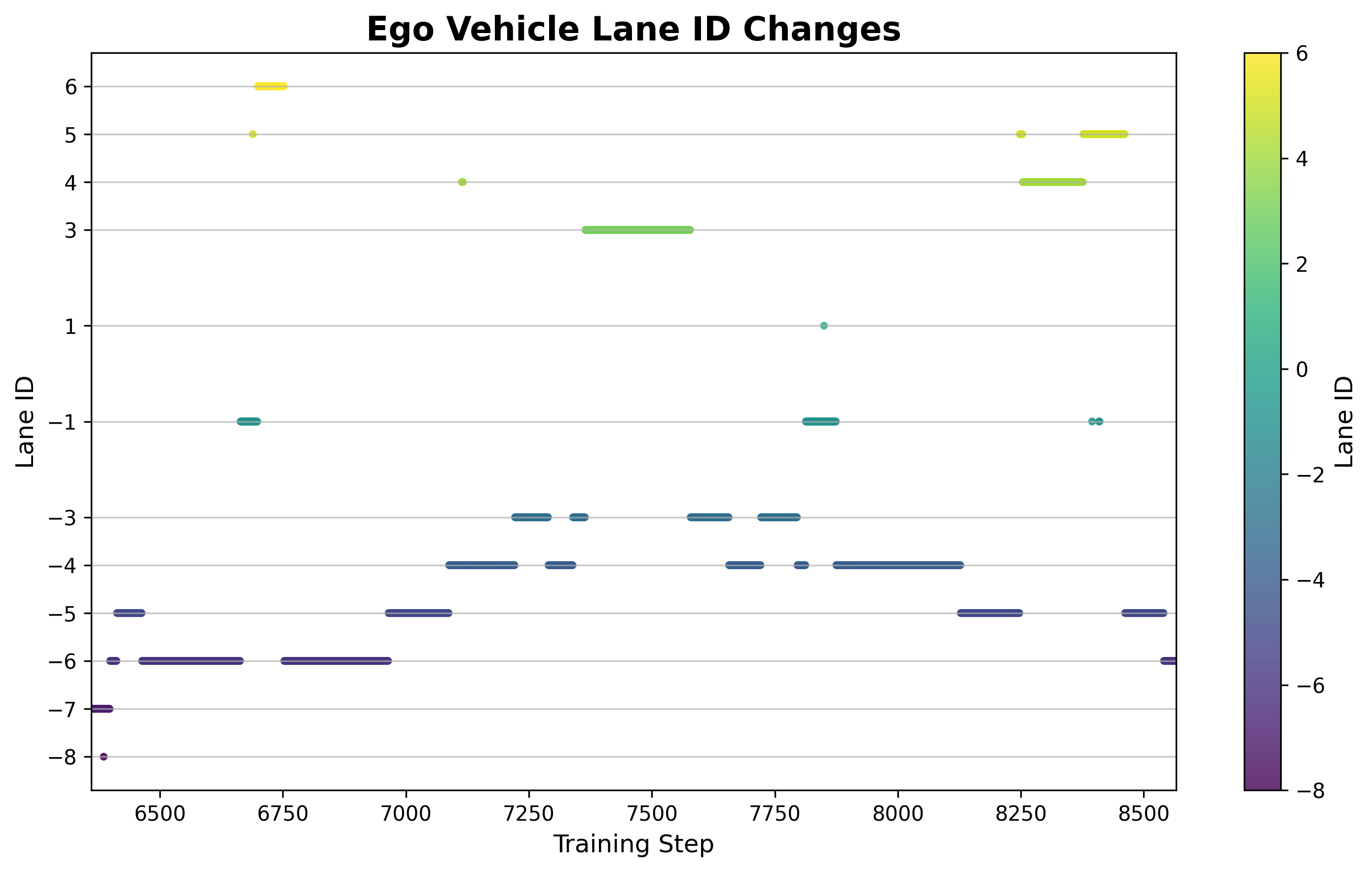
图:训练过程中累计换道次数的变化。前期换道频繁但低效(大量失败换道),中后期换道减少但成功率显著提升,策略学会了在必要时换道而非盲目换道。
6.6 已保存的检查点
项目在 checkpoints/ 目录下保存了 30 个检查点,覆盖从 10,000 步到 270,000 步的完整训练过程:
ppo_carla_autodrive_10006_steps.zip
ppo_carla_autodrive_20253_steps.zip
ppo_carla_autodrive_30253_steps.zip
...
ppo_carla_autodrive_270489_steps.zip每一步 checkpoint 都可用于中断恢复和策略对比实验。
7. 关键代码实现细节
7.1 BridgeHelper:坐标转换
CARLA 使用左手坐标系(X 前,Y 右,Z 上),SUMO 使用右手坐标系,两者轴向相反。BridgeHelper 实现了这个转换:
# 位置转换:SUMO → CARLA
carla_location = carla.Location(
x=sumo_x,
y=-sumo_y, # Y 轴取反
z=0.5
)
# 朝向角转换
carla_rotation = carla.Rotation(
pitch=0,
yaw=math.degrees(-sumo_angle), # 角度取反
roll=0
)7.2 死锁检测与清理
SUMO 中的背景车可能因红灯、拥堵等原因陷入死锁。本项目实现了智能死锁检测:
def _check_and_remove_deadlock(self, vehicle_id):
speed = traci.vehicle.getSpeed(vehicle_id)
wait_time = traci.vehicle.getAccumulatedWaitingTime(vehicle_id)
if speed < 0.1:
if self._is_at_red_light(vehicle_id) and wait_time > 120:
traci.vehicle.remove(vehicle_id) # 红灯等待超时,移除
elif wait_time > 10:
traci.vehicle.remove(vehicle_id) # 非红灯死锁,快速清理7.3 自定义回调:TrafficLoggerCallback
训练过程中自动记录交通数据到 CSV,用于后续分析:
class TrafficLoggerCallback(BaseCallback):
def _on_step(self) -> bool:
infos = self.locals["infos"][0]
self.writer.writerow([
self.num_timesteps,
infos.get('ego_speed_kmh', 0.0),
infos.get('average_speed', 0.0),
infos.get('ego_road_avg_speed', 0.0),
infos.get('current_lane_id', -1)
])
return True8. 项目结构一览
carlaSumoRL/
├── assets/ # SUMO 地图配置、Town06 路网
│ ├── Town06.rou.xml # 交通流生成配置
│ ├── Town06.net.xml # SUMO 路网定义
│ ├── town06.sumocfg # SUMO 仿真配置文件
│ └── *.png # 可视化结果图
├── core/ # 核心仿真逻辑
│ ├── bridge_helper.py # 坐标系转换(368行)
│ ├── carla_simulation.py # CARLA 仿真控制(186行)
│ ├── sumo_simulation.py # SUMO 仿真控制(517行)
│ └── constants.py # 常量定义
├── envs/
│ └── carla_sumo_env.py # Gym 环境定义(469行)
├── checkpoints/ # 30个训练检查点
├── ppo_carla_tensorboard/ # TensorBoard 日志
├── train_ppo.py # 训练入口
├── test_ppo.py # 测试入口
├── plot_training_curve.py # 训练曲线可视化
├── plot_metrics.py # 交通数据分析
└── traffic_log.csv # 实时交通数据日志9. 局限性与未来工作
当前局限
- 观测空间有限:仅用 5 通道射线传感器,未利用视觉输入,高速场景下感知信息不足
- 单主车场景:尚不支持多智能体协同,多车同时换道的交互博弈未建模
- SUMO 车辆行为简单:背景车使用默认 IDM 跟驰模型,缺乏激进/保守驾驶风格的差异化
- 换道判定依赖冷却时间:真实驾驶中换道需要感知-决策-执行的多阶段协调,当前模型做了较大简化
未来方向
- 引入图像输入:使用 CNN 或 Vision Transformer 处理车载相机数据,实现端到端视觉策略
- 多智能体扩展:引入多辆自动驾驶主车,研究交互博弈与对抗场景
- 课程学习:从简单场景(空旷道路)逐步过渡到复杂场景(高密度交通、匝道合流)
- 真实道路验证:将训练好的策略迁移到 Carla_ROS 框架,在实车或硬件在环平台验证
10. 总结
本项目完整实现了一个 CARLA-SUMO 协同仿真 + PPO 强化学习 的自动驾驶换道训练框架。通过双仿真器协同,既保证了主车动力学的真实性,又确保了背景交通流的多样性和挑战性。
项目代码量约 1540 行,结构清晰,覆盖训练-测试-可视化全流程,已保存 30 个检查点供复现和二次开发。如果你对自动驾驶决策规划、强化学习在交通场景中的应用感兴趣,这个框架是一个不错的起点。
项目地址:/home/tartlab/project/outwork/carlaSumoRL/
作者:Kagura Tart | 2026-04-15